
TL;DR: A general face swapping framework that:
🎯 solves no image-level guidance
👩❤️👩 enhances source identity preservation
♾️ is orthogonal and compatiable with existing methods
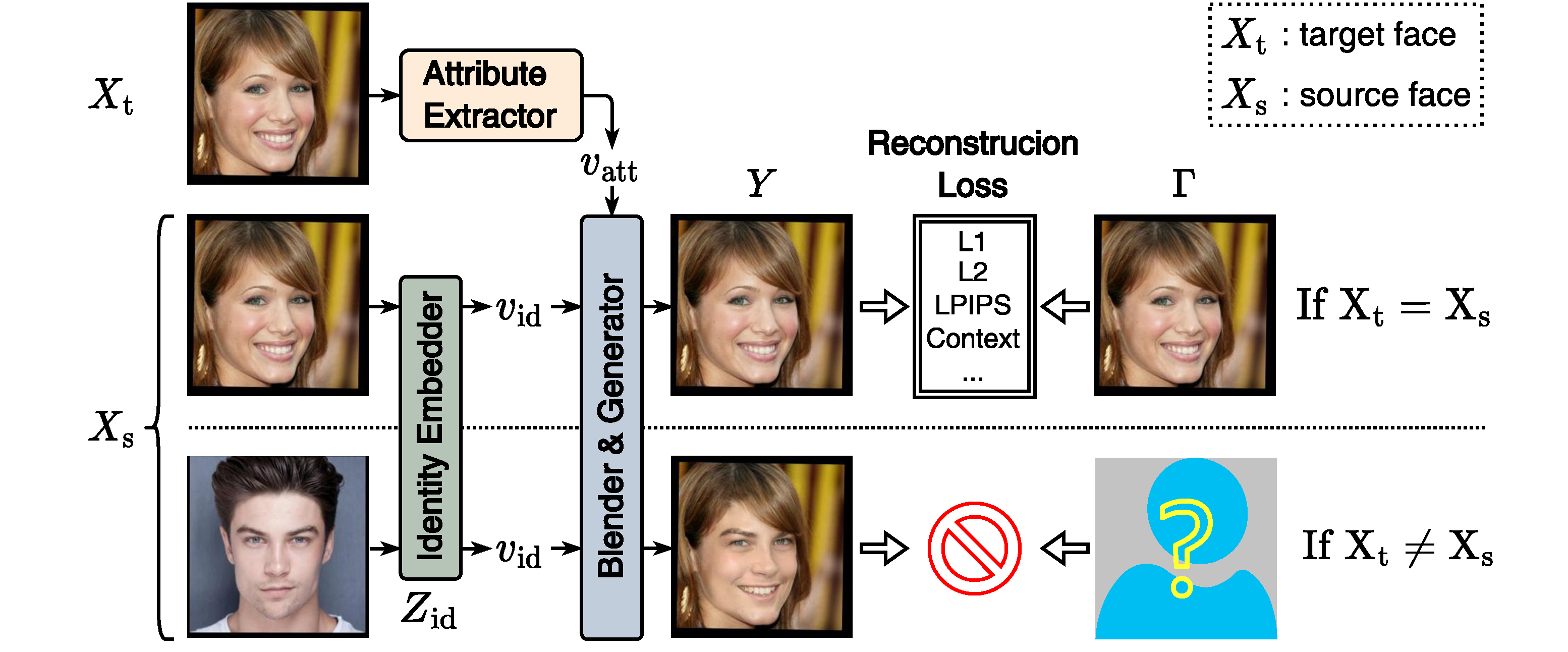
During face swapping training, the re-construction task (used when $X_{\rm{t}}=X_{\rm{s}}$) cannot be used as the proxy anymore when $X_{\rm{t}} \neq X_{\rm{s}}$, lacking pixel-wise supervison $\Gamma$.
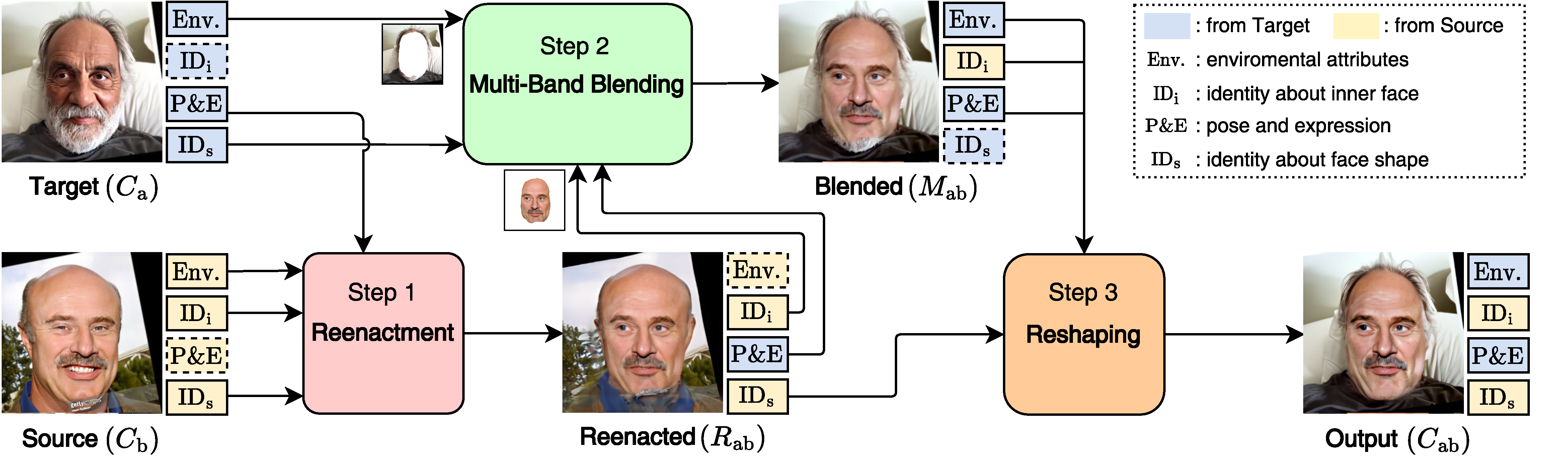
We first use real images $C_{\rm{a}}$ and $C_{\rm{b}}$ to synthesize fake images $C_{\rm{ab}}$ and $C_{\rm{ba}}$. This synthesizing stage preserves the true source identity and target attributes based on Face Reenactment, Multi-Band Blending, and Face Reshaping.
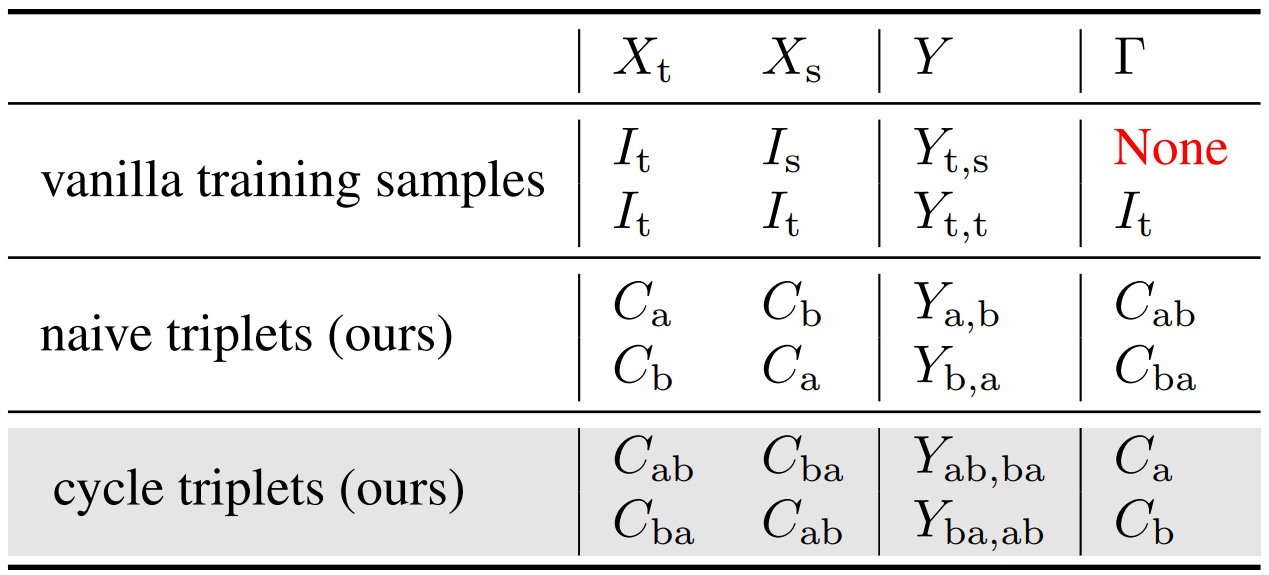
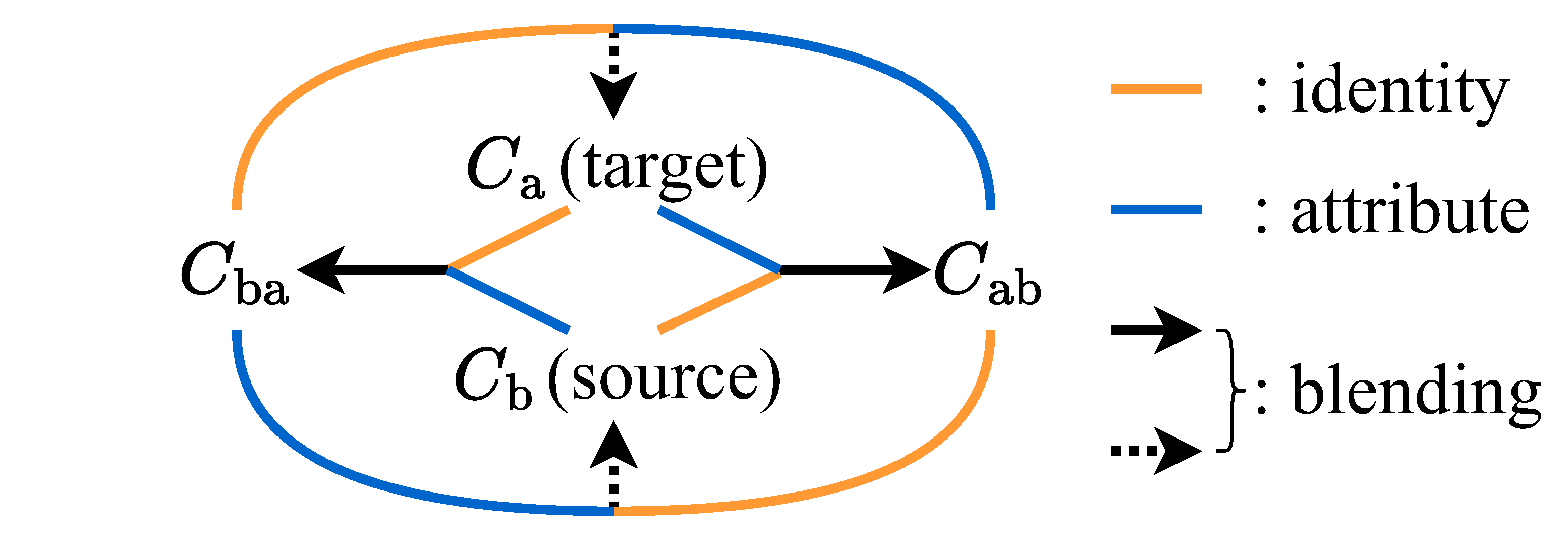
Then based on the cycle relationship, for face swapping training stage, we use fake images as inputs while real images as pixel-level supervisons $\Gamma$, keeping the output domain close to the real and natural distribution and solving the non-supervision issue. In this way, the trainable face swapping network is guided to generate source identity-consistency swapping results, while also keeping target attributes.
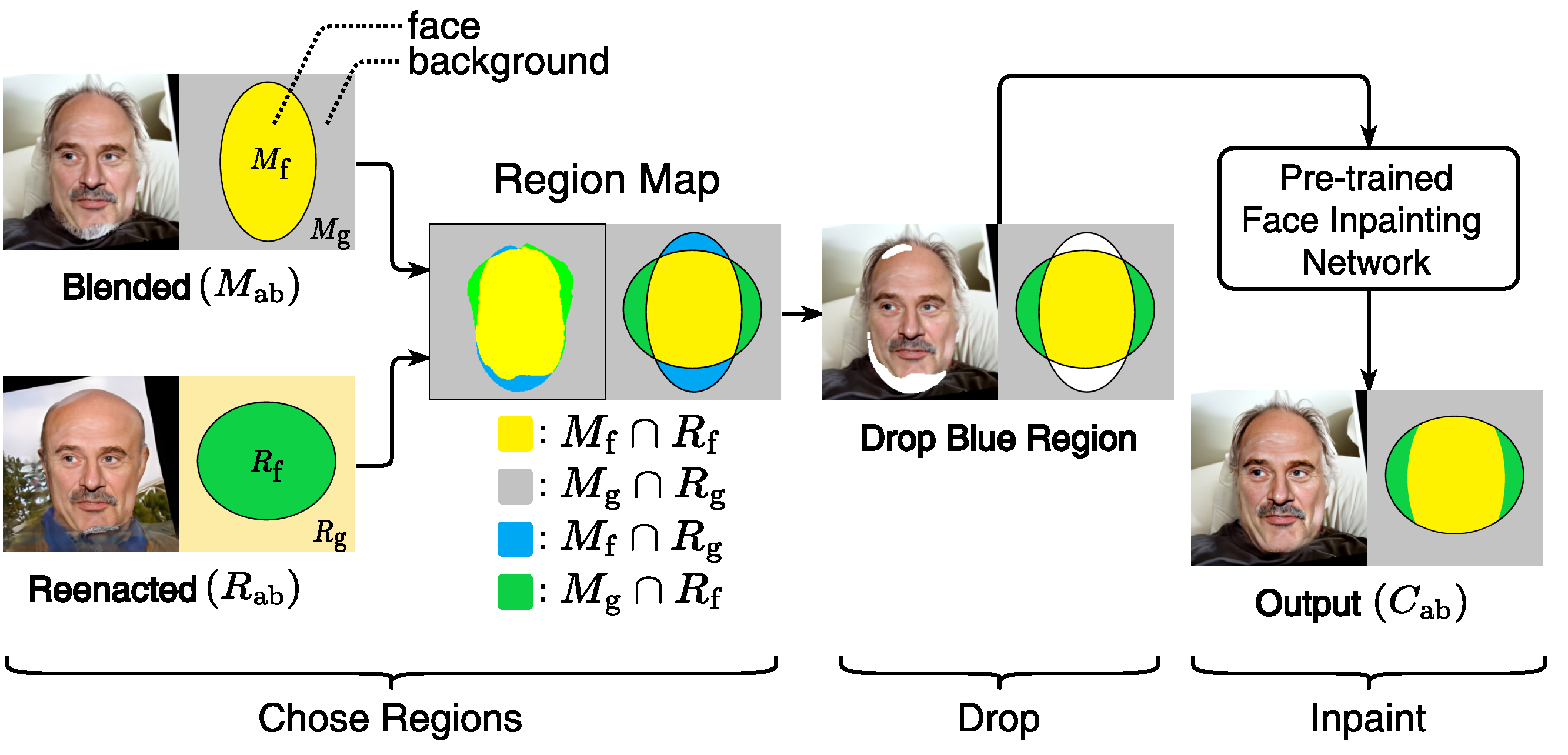
Segmentation-based dropping and inpainting in the Reshaping step.
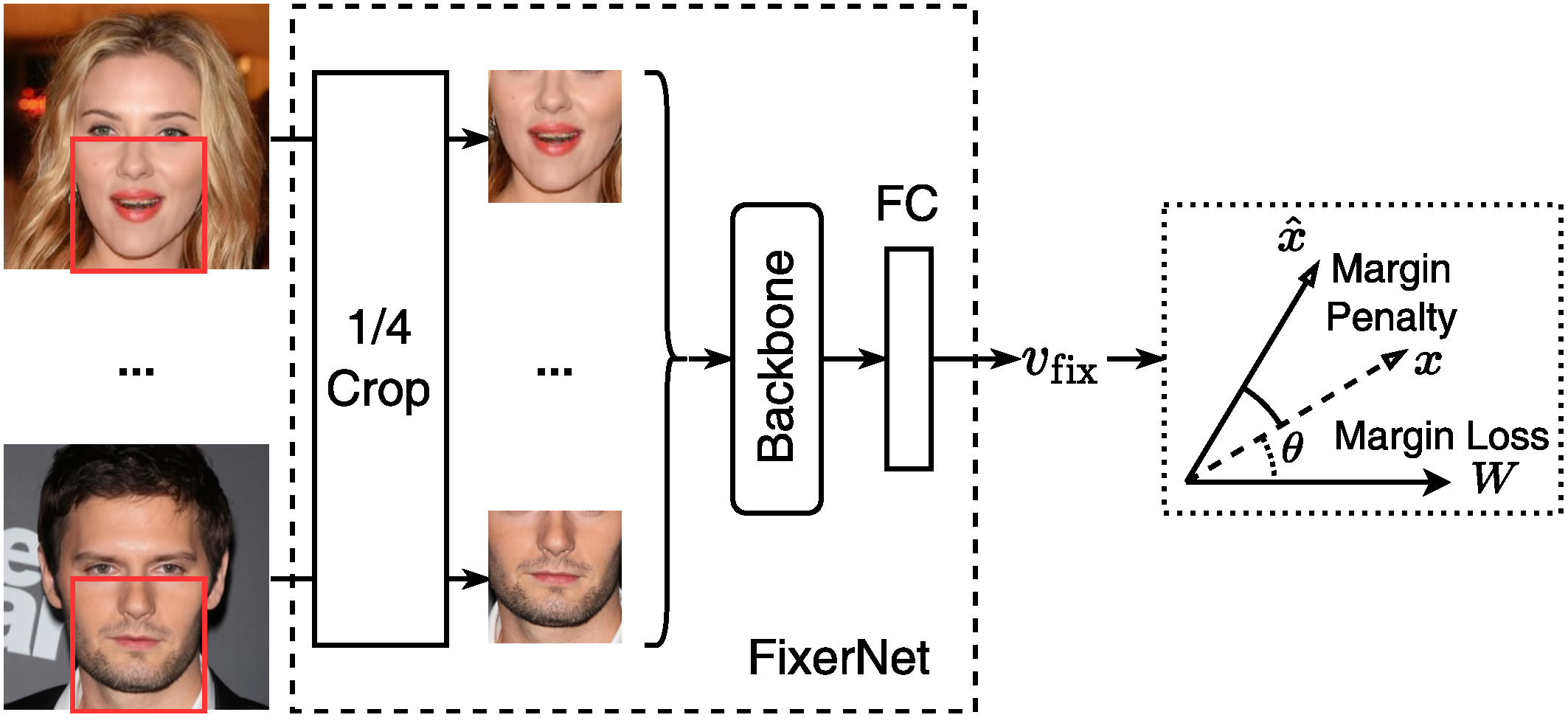
Training stage of the proposed FixerNet. Lower face can be enhanced by $v_{\rm{full}}=[v_{\rm{id}};v_{\rm{fix}}]$.





@article{yuan2023reliableswap,
title={ReliableSwap: Boosting General Face Swapping Via Reliable Supervision},
author={Yuan, Ge and Li, Maomao and Zhang, Yong and Zheng, Huicheng},
journal={arXiv preprint arXiv:2306.05356},
year={2023}
}